BOSCO; Submit Locally, Compute Globally in HTC (High Throughput Computing)
This blog explains why the researchers working in High Throughput Computing (HTC) need BOSCO
Job Submission Manager.
The 1.1 beta release is available for download since December 10, 2012 . Try it! See News BOSCO
All diagrams are from presentations made at OSG Campus Infrastructures Community Workshop at UC Santa Cruz November 14 -15 , 2012
Since 2006, The Center for High Throughput Computing (CHTC) offers computing resources for use by researchers at University of Wisconsin, Madison (UWM). These resources are funded by the National Institute of Health (NIH), the Department of Energy (DOE), the National Science Foundation (NSF), and various grants from the University itself.
How do I reach HTC resources out there?
Many HTC centers, for example Holland Computing Center (HCC) at University of Nebraska campuses uses the "Back of Napkin" approach. They schedule a researcher-user engagement meeting and ask how many jobs the researcher has, what kind of resources he needs, what data products they keep and for how long and so on. Then the questions are: "Does HCC have enough resources for this user, without running into CPU, storage and network bottlenecks? What happens if the needs of a researcher exceed the HCC capacity? The researchers are on their own outside the campus.
The researcher submits jobs to a BOSCO submit node that has an Internet address. He does not need to log in any cluster directly. BOSCO takes care of almost everything else.
The user can be in a Starbucks Coffee Shop or sitting in his home kitchen, using a laptop. You can not get a more cozy local environment than that. The jobs run, from a single script to any clusters whether on Campus Grid and elsewhere on the continent or in the world
The following simple, self explanatory diagrams in Figures 6 to 9 are from Derek Weitzel, a lead architect and developer in BOSCO team. For readers not familiar with HTCondor, Glidein is a mechanism by which one or more grid resources (remote machines) temporarily join a local HTCondor pool.
BOSCO - we hope - builds via software de-facto High Throughput SuperComputing infrastructures, at a scale not possible before.
BOSCO creates wealth in society
Like HTCondor and many other services in HTC, BOSCO main goal is to enable science and discoveries, that will produce much more wealth than just marketing the technology itself. It is a macro-economics goal. For example the GPS service offered today in many industrial consumers products has been made possible by the US Government giving free commercial access to it's geographic location satellites.
Or another example of macro-economic impact is a biophysical modeling at University of Chicago to predict and improve crops world wide
Job Submission Manager.
The 1.1 beta release is available for download since December 10, 2012 . Try it! See News BOSCO
All diagrams are from presentations made at OSG Campus Infrastructures Community Workshop at UC Santa Cruz November 14 -15 , 2012
What is HTC High Throughput Computing?
The name has been coined in a 1997 paper by Miron Livny et al., Mechanisms for High Throughput Computing and this not High Performance Computing (HPC)
The main challenge a HTC environment faces is how to maximize the amount of resources accessible to its customers. Distributed ownership of computing resources is the major obstacle such an environment has to overcome in order to expand the pool of resources from which it can draw upon.For many experimental scientists, scientific progress and quality of research are strongly linked to computing throughput. In other words, most scientists are concerned with how many floating point operations per week or per month they can extract from their computing environment rather than the number of such operations the environment can provide them per second or minute. Floating point operations per second (FLOPS) has been the yardstick used by most High Performance Computing (HPC) efforts to rank their systems. Little attention has been devoted by the computing community to environments that can deliver large amounts o processing capacity over very long periods of time. We refer to such environments as High Throughput Computing (HTC) environments
Since 2006, The Center for High Throughput Computing (CHTC) offers computing resources for use by researchers at University of Wisconsin, Madison (UWM). These resources are funded by the National Institute of Health (NIH), the Department of Energy (DOE), the National Science Foundation (NSF), and various grants from the University itself.
What kind of problems HTC solves
One the better descriptions is from XSEDE web site
High Throughput Computing (HTC) consists of running many jobs that are typically similar and not highly parallel. A common example is running a parameter sweep where the same program is run with varying inputs, resulting in hundreds or thousands of executions of the program. The jobs that make up an HTC computation typically do not communicate with each other and can therefore be executed on physically distributed resources using grid-enabled technologies.HTC workflows may run for weeks or months, unless we grab additional resources from other clusters giving the HTC researchers access to exponentially more hours than they originally had access to.
The mainstream researchers dilemmas
 |
| Fig. 1 Slide presented by Miron Livny |
Researchers are not sysadmins. Yet they are supposed to access and add-on all the clusters they have access to. We don't know exactly where they are. The individual researcher is "likely to use an application he did not write to process data he did not collect on a computer he does not know." (Miron Livny)
 |
| Fig 2 Pre-BOSCO diagram. The researcher is supposed to log in every single cluster accessible and submit jobs in each one. Slide presented by Marco Mambelli |
 | ||
| Fig 3. The climate scientists almost never have enough resources on a single campus grid |
How BOSCO Submits Locally and Computes Globally
BOSCO makes it easy for the researcher to do actual work. A single user must install BOSCO himself on his submit host, which is relatively easy as the local operating system is recognized and BOSCO will download the right binaries automatically.
Once this is done, he can add clusters with different resource managers like LSF, Grid Engine, PBS and HTCondor to his available resources. In BOSCO multi-user, where a team of the researchers share a single submit host running BOSCO as a system service, the local syadmin does all the setup for the users.
From now on BOSCO takes care automatically of all the tedious, repetitive work that researchers had to cope, facing a high probability or making errors or coming across missing information (ssh ports, remote operating systems, passwords, throttling and on and on)
BOSCO is taking care of restrictive firewalls and of the data transfers to and from the execution hosts. It will identify the maximum number of jobs that can be submitted to each host, will throttle the jobs accordingly. It will take the job submission script and will use it with no modification on LSF, Grid Engine, PBS and Condor. To submit also to Open Science Grid, the researcher still needs to have a X509 certificate - we could not work around this requirement for now.
The Multi-Cluster feature allows researchers to submit jobs to many different clusters, using the same script. This is a key feature to enable global job submissions. For a detailed expert description see Multi-Cluster Support from Derek Weitzel blog.
BOSCO is based on HTCondor (the new name of Condor since October 2012)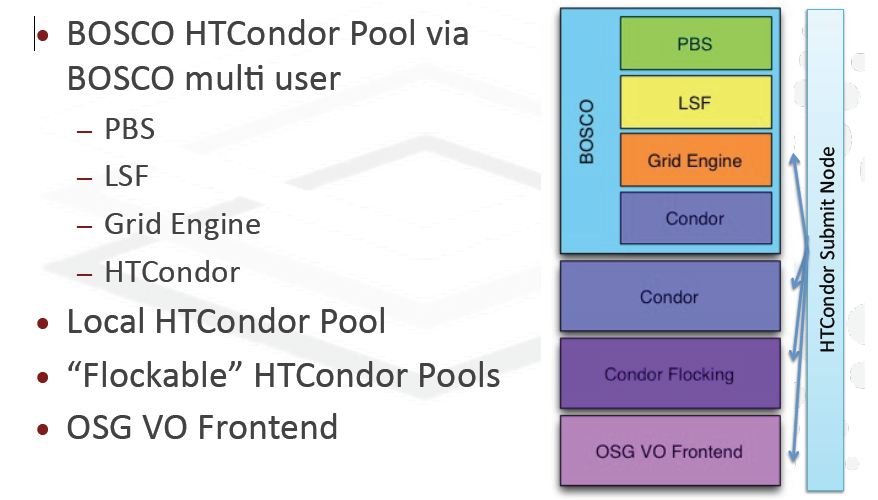 |
Fig. 4 BOSCO uses a single interface for jobs that are processed globally. From Marco Mambelli presentation. Note the list of clusters supported |
 |
| Fig 5: An ideal place for "an out of the box" BOSCO user |
The user can be in a Starbucks Coffee Shop or sitting in his home kitchen, using a laptop. You can not get a more cozy local environment than that. The jobs run, from a single script to any clusters whether on Campus Grid and elsewhere on the continent or in the world
The BOSCO magic?
 |
| Fig. 6 BOSCO (not the user) logs in the cluster and submits the local Glidein |
 |
| Fig. 7 The Glidein is automatically installed to the node |
 |
| Fig. 8 The remote Glidein asks BOSCO to jobs to be sent |
 |
| Fig. 9 BOSCO submits the job to the remote node |
The HTC Researcher Golden Circle
Simon Sinek Golden Circle. We go from inside (Why) to outside (what)
 |
| Fig. 10 The Golden Circle from Inside Out |
Why? Because the science problems I solve cannot be confined to a Campus Grid. How? I need to reach, add and use as many clusters as I can, of any flavor, anywhere in the world. What? There is this tool called BOSCO that makes this possible and it is easy to use. :-)
BOSCO's mission
BOSCO - we hope - builds via software de-facto High Throughput SuperComputing infrastructures, at a scale not possible before.
BOSCO creates wealth in society
Or another example of macro-economic impact is a biophysical modeling at University of Chicago to predict and improve crops world wide
 | ||
| Fig. 11 Simulate crop yields and climate change impact at high-resolution (global extents, multi-scale models, multiple crops – corn, soy, wheat, rice) |
Reminder:
The Bosco 1.1 beta release is available for download now. See News BOSCO
Disclaimer
I am part of the team BOSCO , but the opinions expressed in these blog are personal

Comments