Skip to main content
Search
Search This Blog
The memories of a Product Manager
Thoughts from Silicon Valley
Posts
Showing posts from August, 2013
Show all
August 27, 2013
How to sell performance computing in 2013
August 26, 2013
Is Windows hard to use?
August 22, 2013
Amazon Web Services: We hate you and We love you.
August 16, 2013
Pleasantly Parallel Computing.
August 11, 2013
What a Data Scientist does?
August 02, 2013
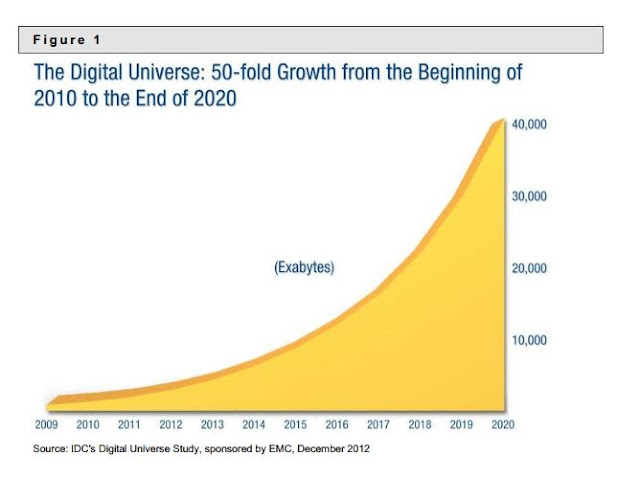
The Kafkian Castle and the Digital Universe
Newer Posts
Older Posts
Home



.jpg)