Skip to main content
Search
Search This Blog
The memories of a Product Manager
Thoughts from Silicon Valley
Posts
Showing posts from May, 2012
Show all
May 22, 2012
An Interview with David Ungar, IBM Research
May 18, 2012
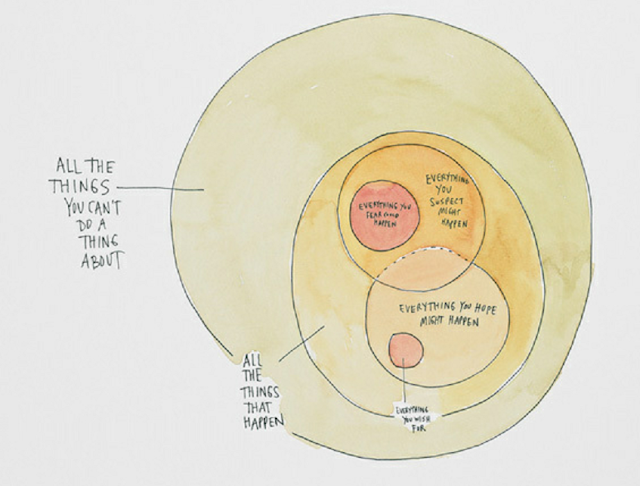
This is the situation we are all in
May 15, 2012
Story of my life and what I learnt raising money in the US.
May 14, 2012
Fractals , JP Morgan; how a CIO can become the scapegoat.
Newer Posts
Older Posts
Home